MediaPipe Gesture Recognizerを使って動画のハンドサインを判定してみます。
忍者の印を画像解析する研究などもあったかと思うのですが、人間の手で作れる形状というのには限界があり、その範囲の中でAIによって形状を判定するというのはよくあるニーズなのかなと考えています。
Google Colabインストール
公式ガイドはこちら
https://ai.google.dev/edge/mediapipe/solutions/vision/gesture_recognizer?hl=ja
ビックリするほどドツボにハマったので、基本的なところを実施していきます。
他のソリューションと違って明示的にGPUを使うフラグはない?ようですね。
!pip install mediapipe
!wget -q https://storage.googleapis.com/mediapipe-models/gesture_recognizer/gesture_recognizer/float16/1/gesture_recognizer.task忘れ去られたジェスチャー?
MediaPipeは2023年にそれまでの従来ソリューション形式から、API利用などを考慮した「新しいソリューション」に刷新されました。
考慮漏れなのか、ジェスチャーがどこにもありません。
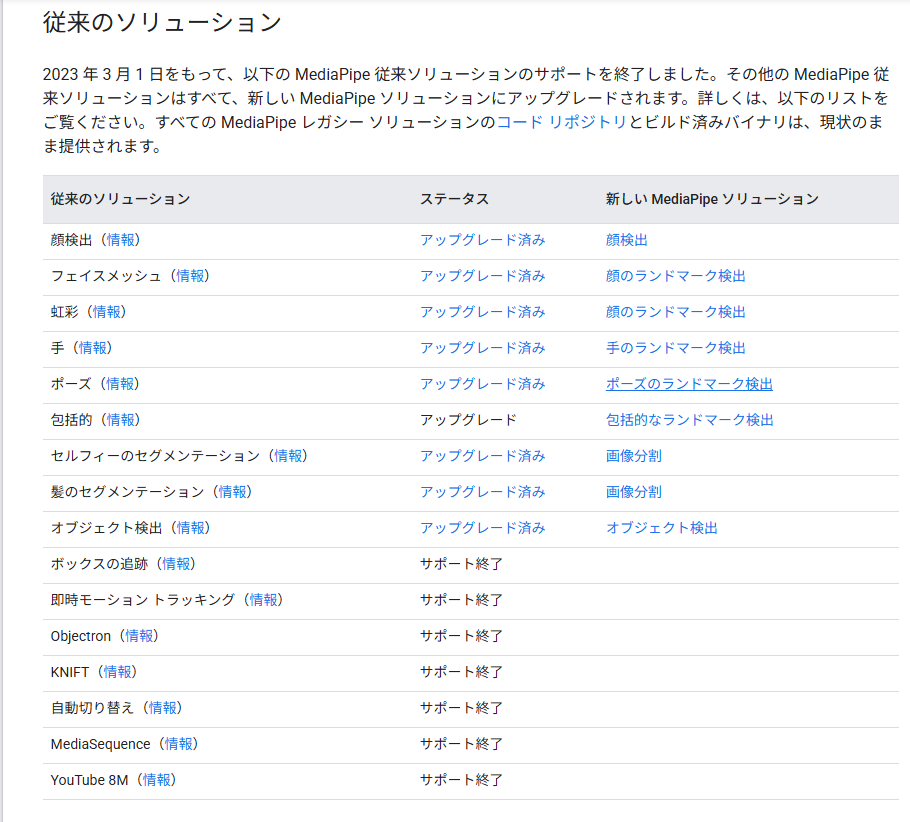
古い公式の資料から流用します。
from matplotlib import pyplot as plt
import mediapipe as mp
from mediapipe.framework.formats import landmark_pb2
plt.rcParams.update({
'axes.spines.top': False,
'axes.spines.right': False,
'axes.spines.left': False,
'axes.spines.bottom': False,
'xtick.labelbottom': False,
'xtick.bottom': False,
'ytick.labelleft': False,
'ytick.left': False,
'xtick.labeltop': False,
'xtick.top': False,
'ytick.labelright': False,
'ytick.right': False
})
mp_hands = mp.solutions.hands
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
def display_one_image(image, title, subplot, titlesize=16):
"""Displays one image along with the predicted category name and score."""
plt.subplot(*subplot)
plt.imshow(image)
if len(title) > 0:
plt.title(title, fontsize=int(titlesize), color='black', fontdict={'verticalalignment':'center'}, pad=int(titlesize/1.5))
return (subplot[0], subplot[1], subplot[2]+1)
def display_batch_of_images_with_gestures_and_hand_landmarks(images, results):
"""Displays a batch of images with the gesture category and its score along with the hand landmarks."""
# Images and labels.
images = [image.numpy_view() for image in images]
gestures = [top_gesture for (top_gesture, _) in results]
multi_hand_landmarks_list = [multi_hand_landmarks for (_, multi_hand_landmarks) in results]
# Auto-squaring: this will drop data that does not fit into square or square-ish rectangle.
rows = int(math.sqrt(len(images)))
cols = len(images) // rows
# Size and spacing.
FIGSIZE = 13.0
SPACING = 0.1
subplot=(rows,cols, 1)
if rows < cols:
plt.figure(figsize=(FIGSIZE,FIGSIZE/cols*rows))
else:
plt.figure(figsize=(FIGSIZE/rows*cols,FIGSIZE))
# Display gestures and hand landmarks.
for i, (image, gestures) in enumerate(zip(images[:rows*cols], gestures[:rows*cols])):
title = f"{gestures.category_name} ({gestures.score:.2f})"
dynamic_titlesize = FIGSIZE*SPACING/max(rows,cols) * 40 + 3
annotated_image = image.copy()
for hand_landmarks in multi_hand_landmarks_list[i]:
hand_landmarks_proto = landmark_pb2.NormalizedLandmarkList()
hand_landmarks_proto.landmark.extend([
landmark_pb2.NormalizedLandmark(x=landmark.x, y=landmark.y, z=landmark.z) for landmark in hand_landmarks
])
mp_drawing.draw_landmarks(
annotated_image,
hand_landmarks_proto,
mp_hands.HAND_CONNECTIONS,
mp_drawing_styles.get_default_hand_landmarks_style(),
mp_drawing_styles.get_default_hand_connections_style())
subplot = display_one_image(annotated_image, title, subplot, titlesize=dynamic_titlesize)
# Layout.
plt.tight_layout()
plt.subplots_adjust(wspace=SPACING, hspace=SPACING)
plt.show()
import mediapipe as mp
import cv2
import math
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
base_options = python.BaseOptions(model_asset_path='gesture_recognizer.task')
options = vision.GestureRecognizerOptions(base_options=base_options)
recognizer = vision.GestureRecognizer.create_from_options(options)
# 画像の読み込み
image = mp.Image.create_from_file("/content/input.png")
img_np = image.numpy_view()
# リサイズ処理
DESIRED_HEIGHT = 480
DESIRED_WIDTH = 480
h, w = img_np.shape[:2]
if h < w:
new_width = DESIRED_WIDTH
new_height = math.floor(h / (w / DESIRED_WIDTH))
else:
new_height = DESIRED_HEIGHT
new_width = math.floor(w / (h / DESIRED_HEIGHT))
resized_np = cv2.resize(img_np, (new_width, new_height))
resized_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=resized_np)
# ジェスチャー
recognition_result = recognizer.recognize(resized_image)
print("Recognition result:", recognition_result)
if recognition_result.gestures and len(recognition_result.gestures[0]) > 0:
top_gesture = recognition_result.gestures[0][0]
else:
top_gesture = None
# 手のランドマーク確認
hand_landmarks = recognition_result.hand_landmarks
if hand_landmarks:
if not isinstance(hand_landmarks[0], (list, tuple)):
hand_landmarks = [hand_landmarks]
else:
hand_landmarks = []
result_tuple = (top_gesture, hand_landmarks)
images = [resized_image]
results = [result_tuple]
display_batch_of_images_with_gestures_and_hand_landmarks(images, results)結果
None
検出できるジェスチャー
デフォルトでは、以下の6つのジェスチャーを判定可能とされています。
1 - 握りこぶし (Closed_Fist)
手を握って指を曲げた状態。たとえば、拳を作っている状態
2 - 開いた手のひら (Open_Palm)
手を広げ、全ての指が伸びた状態。手全体が見える状態
3 - 指を上に向けたジェスチャー (Pointing_Up)
人差し指を伸ばして上方向を指している状態
4 - 親指を下に向けたジェスチャー (Thumb_Down)
親指だけが下向きになっている状態
5 - 親指を上に向けたジェスチャー (Thumb_Up)
親指だけが上向きになっている状態
6 - ピースサイン (Victory)
人差し指と中指を立てたジェスチャー
7 - ラブ / I Love You (ILoveYou)
手の形で愛情を表現するジェスチャー。一般的には「I Love You」の意味を示します。Pointingだけだとありがたいのですが、かなり上方向を向いている必要がありそうです。
90度ずつ回転させながら判定
多少強引ですが、90度ずつインプットを回転させながら判定させてみました。
コードはこちら
import cv2
import mediapipe as mp
import math
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
import matplotlib.pyplot as plt
mp_drawing = mp.solutions.drawing_utils
import mediapipe.framework.formats.landmark_pb2 as landmark_pb2
base_options = python.BaseOptions(model_asset_path='gesture_recognizer.task')
options = vision.GestureRecognizerOptions(base_options=base_options)
recognizer = vision.GestureRecognizer.create_from_options(options)
original_image = mp.Image.create_from_file("/content/new-input.jpg")
img_np = original_image.numpy_view()
rotation_angles = [0, 90, 180, 270]
images = []
results = []
for angle in rotation_angles:
print(f"\n--- {angle}度回転 ---")
# 角度に応じた回転処理
if angle == 0:
rotated_np = img_np
elif angle == 90:
rotated_np = cv2.rotate(img_np, cv2.ROTATE_90_CLOCKWISE)
elif angle == 180:
rotated_np = cv2.rotate(img_np, cv2.ROTATE_180)
elif angle == 270:
rotated_np = cv2.rotate(img_np, cv2.ROTATE_90_COUNTERCLOCKWISE)
rotated_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=rotated_np)
# ジェスチャー認識
recognition_result = recognizer.recognize(rotated_image)
# トップジェスチャーの抽出(存在しなければ None)
if recognition_result.gestures and len(recognition_result.gestures) > 0 and len(recognition_result.gestures[0]) > 0:
top_gesture = recognition_result.gestures[0][0]
else:
top_gesture = None
print("トップジェスチャー:", top_gesture)
hand_landmarks = recognition_result.hand_landmarks
if hand_landmarks:
if not isinstance(hand_landmarks[0], (list, tuple)):
hand_landmarks = [hand_landmarks]
else:
hand_landmarks = []
# 結果がある(ジェスチャーまたはランドマークが検出される)場合のみリストに追加
if top_gesture is not None or len(hand_landmarks) > 0:
images.append(rotated_image)
results.append((top_gesture, hand_landmarks))
else:
print(f"{angle}度回転: 結果なし。")
if images:
display_batch_of_images_with_gestures_and_hand_landmarks(images, results)
else:
print("どの回転角度でも結果が検出されませんでした。")
両手検出は至難の業?
「検出できる手の最大数は GestureRecognizer によって決まります」とあるので、オプションパラメータを2に設定して両手の検出にトライしたのですがかなりキビシめです。
options = vision.GestureRecognizerOptions(base_options=base_options, num_hands=2)画像をぱくたそさまからお借りしました。
これで両手ブイサインではないという判定のようです。

今度は両手がブイサインであると検出できました。
角度とかが関係しているのでしょうか。

ここまで厳しいなら、YOLO系で判定するとかしたほうが良いかも?とすら思ってしまいました。
動画モードもあるのですが、回転をさせる必要があるとすると、結局は画像ベースの判定になってしまいますし。
I Love You のジェスチャー
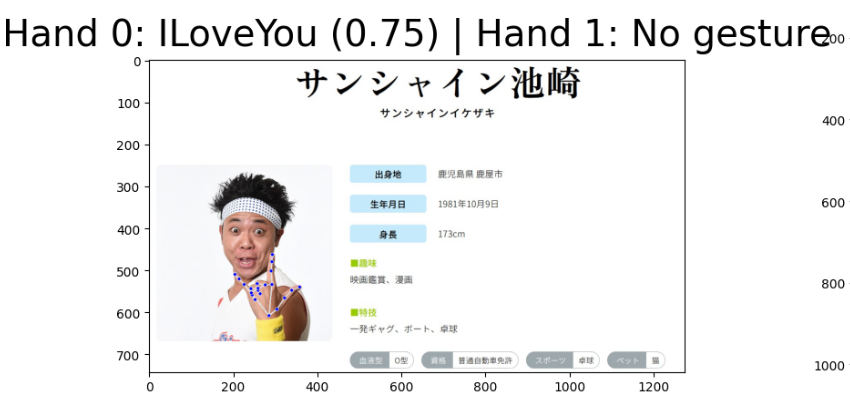
サンシャイン池崎氏のポーズが I Love You のハンドジェスチャーだそうで…